Semi-supervised text classification using doc2vec and label spreading
Here is a simple way to classify text without much human effort and get a impressive performance.
It can be divided into two steps:
- Get train data by using keyword classification
- Generate a more accurate classification model by using doc2vec and label spreading
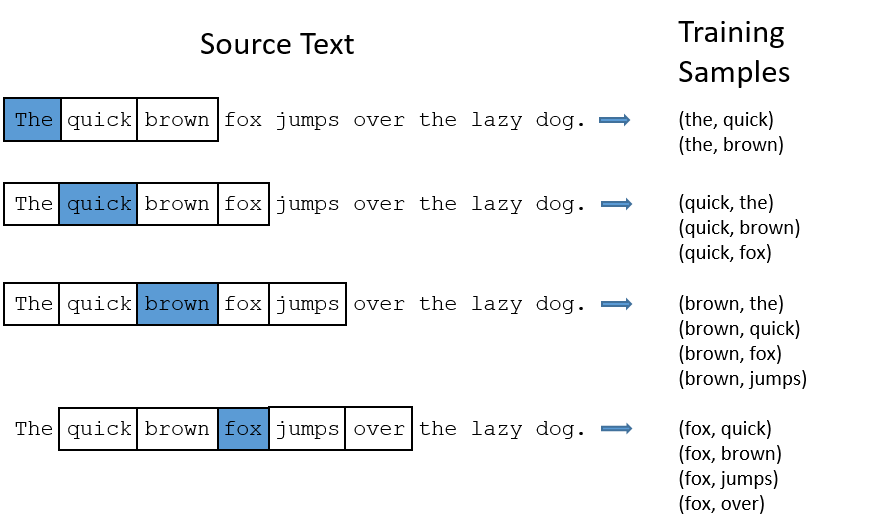
Keyword-based Classification
Keyword based classification is a simple but effective method. Extracting the target keyword is a monotonous work. I use this method to automatic extract keyword candidate.